RISC-V中断与异常
trap(陷阱)可以分为异常与中断。在RISC v下,中断有三种来源:software interrupt、timer interrupt(顾名思义,时钟中断)、external interrupt。
有同学可能见过NMI,但是这是一种中断类型而非中断来源。Non-maskable interrupt,不可屏蔽中断,与之相对的就是可屏蔽中断。NMI都是硬件中断,只有在发生严重错误时才会触发这种类型的中断。
有同学可能接触过Linux中的软中断,即softirq,但是请注意software interrupt与softirq是完完全全不一样的。如果你没有接触过softirq就请现在就暂停本文去了解一下,否则把Linux中的softirq与software interrupt搞混是会贻笑大方的。
本文将全面介绍RISC v下的中断发送与处理、软件中断、用户态中断和特权级转换,并结合xv6内核、rcore、Linux内核等实现进行介绍。
与中断有关的寄存器
下面所述的都是软件中断、外部中断和异常相关的内容,时钟中断比较特殊将单独介绍。
常规中断
M-mode的寄存器
mstatus,mtvec,medeleg,mideleg,mip,mie,mepc,mcause,mtval
S-mode的寄存器
sstatus,stvec,sip,sie,sepc,scause,stval,satp
在后文中,我们可能会有xstatus`xtvec`等的写法,其中x表示特权级m或者s或者u(u仅仅在实现了用户态中断的CPU上存在)。
mcause
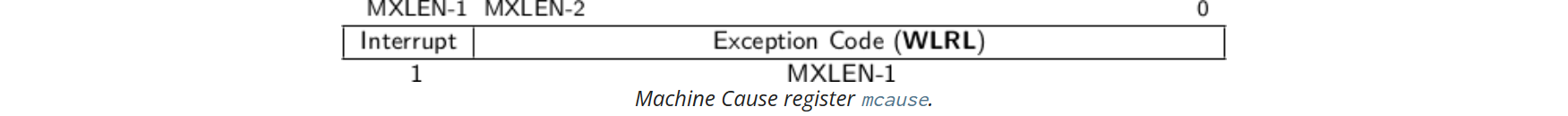
如果陷阱是由中断引起的,则mcause寄存器中的“Interrupt”位被设置。Exception Code字段用于标识最后一个异常或中断的代码。下表列出了可能的机器级异常代码。异常代码是WLRL字段,因此仅保证包含受支持的异常代码。
(PS: 读者可能疑惑为啥在mcause中会存在Supervissor software interrupt [TODO])
mstatus

MIE与SIE是全局中断使能位。当xIE为1时,允许在x特权级发生中断,否则不允许中断。
当hart处于x特权级时,当xIE为0时,x特权级的中断被全部禁用,否则被全部启用。当xIE为0时,对于任意的w<x,w特权级的中断都是处于全局禁用状态。对于任意的y>x,y特权级的中断默认处于全局启用状态,无论xIE是否为1。
为支持嵌套陷阱,每个可以响应中断的特权模式x都有一个两级中断使能位和特权模式堆栈。xPIE保存陷阱之前活动的中断使能位的值,xPP保存之前的特权模式。xPP字段只能保存x及以下特权模式,因此MPP为两位宽,SPP为一位宽。当从特权模式y进入特权模式x时,xPIE设置为xIE的值;xIE设置为0;xPP设置为y。对于MPP,可以设置的值有0b00(用户模式),0b01(S-mode),0b10(reserved),0b11(M-mode)
在M模式或S模式中,使用MRET或SRET指令返回陷阱。执行xRET指令时,将xIE设置为xPIE;将xPIE设置为1;假设xPP值为y,则将特权模式更改为y;将xPP设置为U(如果不支持用户模式,则为M)。如果xPP≠M,则xRET还会设置MPRV=0。
mtvec
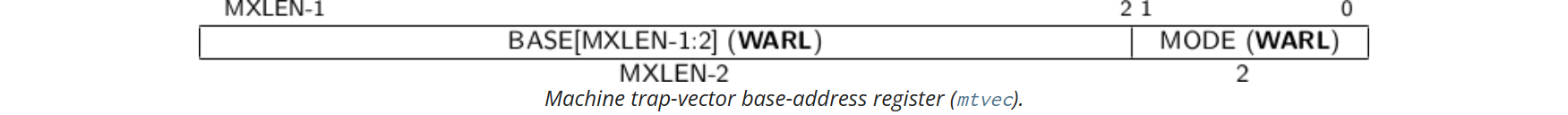
mtvec记录的是异常处理函数的起始地址。BASE字段中的值必须始终对齐于4字节边界,并且MODE设置可能会对BASE字段中的值施加额外的对齐约束。
MODE目前可以取两种值:

如果MODE为0,那么所有的异常处理都有同一个入口地址,否则的话异常处理的入口地址是BASE+4*CAUSE。(cause记录在xcause中)
要求异常处理函数的入口地址必须是4字节对齐的。
medeleg与mideleg
默认情况下,各个特权级的陷阱都是被捕捉到了M-mode,可以通过代码实现将trap转发到其它特权级进行处理,为了提高转发的性能在CPU级别做了改进并提供了medeleg和mideleg两个寄存器。
medeleg (machine exception delegation)用于指示转发哪些异常到S-mode;mideleg(machine interrupt delegation)用于指示转发哪些中断到S-mode。
当将陷阱委托给S模式时,scause寄存器会写入陷阱原因;sepc寄存器会写入引发陷阱的指令的虚拟地址;stval寄存器会写入特定于异常的数据;mstatus的SPP字段会写入发生陷阱时的活动特权级;mstatus的SPIE字段会写入发生陷阱时的SIE字段的值;mstatus的SIE字段会被清除。mcause、mepc和mtval寄存器以及mstatus的MPP和MPIE字段不会被写入。
假如被委托的中断会导致该中断在委托者所在的特权级屏蔽掉。比如说M-mode将一些中断委托给了S-mode,那么M-mode就无法捕捉到这些中断了。
mip与mie
mip与mie是分别用于保存pending interrupt和pending interrupt enable bits。每个中断都有中断号i(定义在mcause表中),每个中断号如果被pending了,那么对应的第i位就会被置为1. 因为RISC v spec定义了16个标准的中断,因此低16bit是用于标准用途,其它位则平台自定义。
如下图所示是低16bit的mip与mie寄存器。其实比较好记忆,只需要知道mcause中的中断源即可。例如SSIP就是supervisor software interrupt pending, SSIE就是supervisor software interrupt enable。
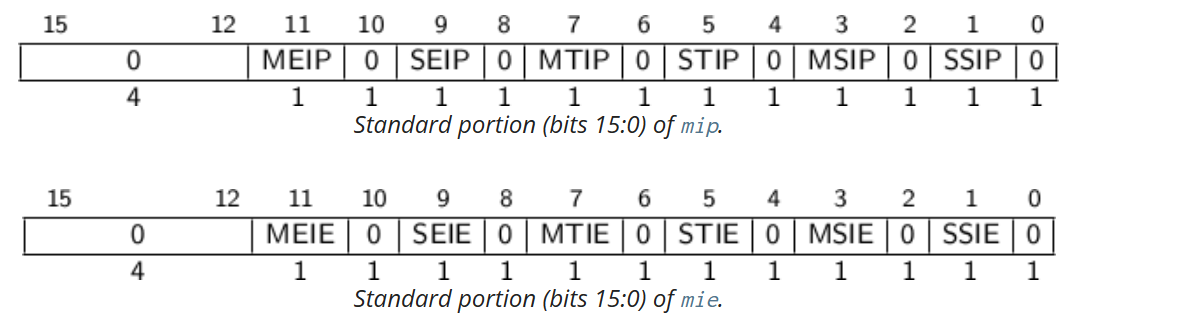
如果全局中断被启用了,且mie和mip的第i位都为1,那么中断i将会被处理。默认情况下,如果当前特权级小于M或者当前特权级为M切MIE是1的话,全局中断就是被启用的;如果mideleg的第i位为1,那么当当前特权级为被委托的特权级x(或者是小于x),且mstatus中的xIE为1那么就认为是全局中断是被启用的。
寄存器 mip 中的每个位都可以是可写的或只读的。当 mip 中的第 i 位可写时,可以通过向该位写入 0 来清除挂起的中断 i。如果中断 i 可以变为挂起但 mip 中的位 i 是只读的,则实现必须提供一些其他机制来清除挂起的中断。如果相应的中断可以变为挂起,则 mie 中的位必须是可写的。不可写的 mie 位必须硬连线为零。
位 mip .MEIP 和 mie .MEIE 是M-mode外部中断的中断挂起和中断允许位。 MEIP 在 mip 中是只读的,由平台特定的中断控制器设置和清除。
位 mip .MTIP 和 mie .MTIE 是M-mode定时器中断的中断挂起和中断允许位。 MTIP 在 mip 中是只读的,通过写入映射到内存的mtimecmp来清除。
位 mip .MSIP 和 mie .MSIE 是机器级软件中断的中断挂起和中断允许位。 MSIP 在 mip 中是只读的,通过访问内存映射控制寄存器写入,远程 harts 使用这些寄存器来提供M-mode处理器间中断。 hart 可以使用相同的内存映射控制寄存器写入自己的 MSIP 位。
如果实现了S-mode,位 mip .SEIP 和 mie .SEIE 是S-mode外部中断的中断挂起和中断允许位。 SEIP 在 mip 中是可写的,并且可以由 M 模式软件写入以向 S 模式指示外部中断正在挂起。此外,平台级中断控制器(PLIC)可以生成S-mode外部中断。SEIP位是可写的,因此需要根据SEIP和外部中断控制器的信号进行逻辑或运算的结果,来判断是否有挂起的S-mode外部中断。当使用 CSR 指令读取 mip 时, rd 目标寄存器中返回的 SEIP 位的值是mip.SEIP与来自中断控制器的中断信号的逻辑或。但是,CSRRS 或 CSRRC 指令的读取-修改-写入序列中使用的值仅包含软件可写 SEIP 位,忽略来自外部中断控制器的中断值。
SEIP 字段行为旨在允许更高权限层干净地模拟外部中断,而不会丢失任何真实的外部中断。因此,CSR 指令的行为与常规 CSR 访问略有不同。
如果实现了S-mode, mip .STIP 和 mie .STIE 是S-mode定时器中断的中断挂起和中断允许位。 STIP 在 mip 中是可写的,并且可以由 M 模式软件编写以将定时器中断传递给 S 模式。
位 mip .SSIP 和 mie .SSIE 是管理级软件中断的中断挂起和中断允许位。 SSIP 在 mip 中是可写的。
S-mode的interprocessor interrrupts与实现机制有关,有的是通过调用System-Level Exception Environment(SEE)来实现的,调用SEE最终会导致在M-mode将MSIP位置为1. 我们只允许hart修改它自己的SSIP bit,不允许修改其它hart的SSIP,这是因为其它的hart可能处于虚拟化的状态、也可能被更高的descheduled。因此我们必须通过调用SEE来实现interprocessor interrrupt。M-mode是不允许被虚拟化的,而且已经是最高特权级了,因此可以直接修改其它位的MSIP,通常是使用非缓冲IO写入memory-mapped control registers来实现的,具体依赖于平台的实现机制。
多个同时中断按以下优先级递减顺序处理:MEI、MSI、MTI、SEI、SSI、STI。异常的优先级低于所有中断。
mepc
当trap陷入到M-mode时,mepc会被CPU自动写入引发trap的指令的虚拟地址或者是被中断的指令的虚拟地址。
mtval
当trap陷入到M-mode时,mtval会被置零或者被写入与异常相关的信息来辅助处理trap。当触发硬件断点、地址未对齐、access fault、page fault时,mtval记录的是引发这些问题的虚拟地址。
stastus

与中断相关的字段是SIE、SPIE、SPP。
SPP 位指示处理器进入 supervisor 模式之前的特权级别。当发生陷阱时,如果该陷阱来自用户模式,则 SPP 设置为 0;否则设置为 1。当执行 SRET 指令从陷阱处理程序返回时,如果 SPP 位为 0,则特权级别设置为用户模式;如果 SPP 位为 1,则特权级别设置为 supervisor 模式;然后将 SPP 设置为 0。
SIE 位在 supervisor 模式下启用或禁用所有中断。当 SIE 为零时,在 supervisor 模式下不会进行中断处理。当处理器在用户模式下运行时,忽略 SIE 的值,并启用 supervisor 级别的中断。可以使用 sie 寄存器 来禁用单个中断源。
SPIE 位指示陷入 supervisor 模式之前是否启用了 supervisor 级别的中断。当执行跳转到 supervisor 模式的陷阱时,将 SPIE 设置为 SIE,并将 SIE 设置为 0。当执行 SRET 指令时,将 SIE 设置为 SPIE,然后将 SPIE 设置为 1。
其它s特权级寄存器
stvec, sip, sie,sepc, scause, stval与m-mode的相应寄存器区别不大,读者可自行参阅RISC v的spec。
satp比较特殊,在M-mode没有对应的寄存器,因为M-mode没有分页,satp记录的是根页表物理地址的页帧号。在从U切换到S时,需要切换页表,也即是切换satp的根页表物理地址的页帧号。
特权级转换
我在这里只介绍了U和S之间的切换,其实S和M之间的切换过程也是一样的,只不过使用到的寄存器不一样了而已。比如说保存pc的寄存,S保存U的pc值使用的是sepc,M保存S的pc使用的是mepc。此外,U切换到S时一般不需要切换页表,这是因为进程的虚拟地址空间的高地址处就影射了内核空间。因此从用户态切换到内核态时,是不需要切换页表的。从S切换到M时不需要切换页表,因为M没有实现分页。
特权级切换一定不会切换页表吗?也不一定。这个与系统设计有关。像Linux下,用户进程地址空间就映射了内核空间,因此不需要切换页表。而如果在设计时,没有映射内核空间页表,那肯定就需要切换页表啦。把页表从进程的虚存切换到内核的虚存。
那么问题是,为什么Linux在设计时将内核空间与进程空间设计到同一套地址空间中呢?这是为了提高访问效率。如果执行系统调用时发生了页表切换,那么势必也会刷新TLB;此外在进程将数据传递给内核时,内核也可以很方便地对进程的地址空间进行访问。
如果不在同一套地址空间,内核和进程如何相互进行地址访问呢?
- 如果不是同一套地址空间,那么就需要在系统调用时,切换页表,硬件不会自动切换页表,因此需要内核自己实现。这个过程应该是:首先从用户栈切换到内核栈,然后保存用户态的上下文(各种寄存器),最后切换页表。值得注意的是,这些上下文保存的代码必然也是要被映射到进程虚拟地址空间的,因为此时还没有切换页表。
- 当页表切换完毕之后,如果内核要从进程中拷贝数据要怎么办呢?此时已经切换了页表了,而传入的参数依然是进程的虚存的虚拟地址,这就需要手动对虚拟地址进行转换,转换到物理地址。这个过程可以通过代码实现,首先找到进程的根页表的地址,然后逐级解析找到物理地址。找到物理地址之后,使用__va的内核API将物理地址转换为内核空间的虚拟地址,然后再进行访问。
U与S之间的切换
U切换到S
当执行一个trap时,除了timer interrupt,所有的过程都是相同的,硬件会自动完成下述过程:
- 如果该trap是一个设备中断并且
sstatus的SIE bit为0,那么不再执行下述过程 - 通过置零SIE禁用中断
- 将pc拷贝到
sepc - 保存当前的特权级到
sstatus的SPP字段 - 将
scause设置成trap的原因 - 设置当前特权级为supervisor
- 拷贝
stvec(中断服务程序的首地址)到pc - 开始执行中断服务程序
CPU不会自动切换到内核的页表,也不会切换到内核栈,也不会保存除了pc之外的寄存器的值,内核需要自行完成。对于Linux而言,内核空间与用户态空间是使用的同一套页表,不需要切换页表。详情可以参考用户态进程的虚拟内存布局。内核空间一般位于进程的高虚拟地址空间。
对于没有开启分页,如何切换特权级可以参考:实现特权级的切换 - rCore-Tutorial-Book-v3 3.6.0-alpha.1 文档
如果启用了分页,当陷入到S模式时,CPU没有切换页表(换出进程的页表,换入内核页表),内核需要自行切换页表,参考:内核与应用的地址空间 - rCore-Tutorial-Book-v3 3.6.0-alpha.1 文档 和 基于地址空间的分时多任务 - rCore-Tutorial-Book-v3 3.6.0-alpha.1 文档 。
其实切换页表的过程也很简单,只需要将内核的页表地址写入satp寄存器即可。
在执行中断服务例程时还需要首先判断sstatus的SPP字段是不是0,如果是0表示之前是U模式,否则表示S模式。如果SPP是1那就出现了严重错误(因为既然是从U切换到S的过程,怎么可以SPP是S模式呢?当然,如果是内核执行时发生了中断SPP是1那自然是对的,内核执行时发生中断时如果检查SPP是0那也是严重的错误)。
S切换到U
在从S切换到U时,要手动清除sstatus的SPP字段,将其置为零;将sstatus的SPIE字段置为1,启用用户中断;设置sepc为用户进程的PC值(你可能疑惑在U转换到S时不是已经将用户进程的保存在了sepc了吗?因为在S-mode也会发生中断呀,那么sepc就会被用来保存发生中断位置时的PC了)。如果启用了页表,就需要想还原用户进程的页表,即将用户进程的页表地址写入satp,之后恢复上下文,然后执行sret指令,硬件会自动完成以下操作:
- 从
sepc寄存器中取出要恢复的下一条指令地址,将其复制到程序计数器pc中,以恢复现场; - 从
sstatus寄存器中取出用户模式的相关状态,包括中断使能位、虚拟存储模式等,以恢复用户模式的状态; - 将当前特权模式设置为用户模式,即取消特权模式,回到用户模式。
S与M之间的切换
S切换到M
S切换到M与从U切换到M类似,都是从低特权级到高特权级的切换。在S运行的代码,也可以通过ecall指令陷入到M中。
- S-mode的代码执行一个指令触发了异常或陷阱,例如环境调用(ECALL)指令
- 处理器将当前的 S-mode 上下文的状态保存下来,包括程序计数器 (PC)、S-mode 特权级别和其他相关寄存器,保存在当前特权级别堆栈中的S-MODE陷阱帧(trap frame,其实就是一个页面)中
- 处理器通过将 mstatus 寄存器中的 MPP 字段设置为 0b11(表示先前的模式是S模式)将特权级别设置为 M-mode
- 处理器将程序计数器设置为在 M-mode 中的陷阱处理程序例程的地址
- 处理器还在 mstatus 寄存器中设置 M-mode 中断使能位 (MIE) 为 0,以在陷阱处理程序中禁用中断
系统调用的实现
系统调用是利用异常机制实现的。在mcause中我们看到有Environment call from U-mode和Environment call from S-mode两个异常类型。那么如何触发这两个异常呢?分别在U-mode和S-mode执行ecall指令就能触发这两个异常了。
异常触发之后,就会被捕捉到M-mode(我之前提过,RISC v下默认是把所有的异常、中断捕捉到M-mode,当且仅当对应的陷阱被委托给了其它模式才会陷入到被委托的模式中)。假如说
地址空间布局
启用分页模式下,内核代码的访存地址也会被视为一个虚拟地址并需要经过 MMU 的地址转换,因此我们也需要为内核对应构造一个地址空间,它除了仍然需要允许内核的各数据段能够被正常访问之后,还需要包含所有应用的内核栈以及一个 跳板 (Trampoline) 。
值得注意的是,下面是是rCore的内核地址空间分布,不同的OS设计不同。
| 高256GB内核地址空间 | 低256GB内核地址空间 |
|---|---|
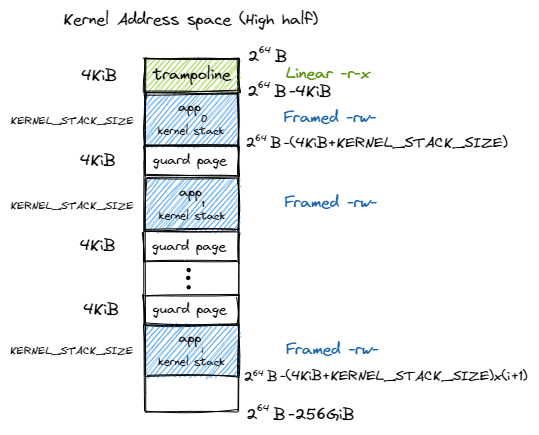 |
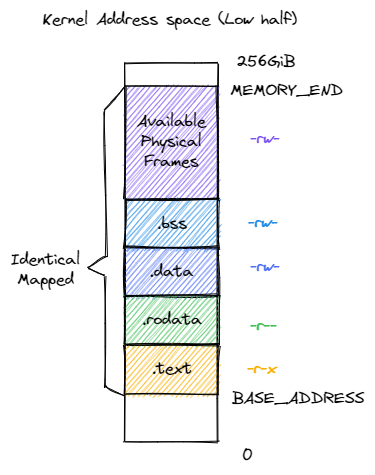 |
| 应用程序高256GB地址空间 | 应用程序低256GB地址空间 |
|---|---|
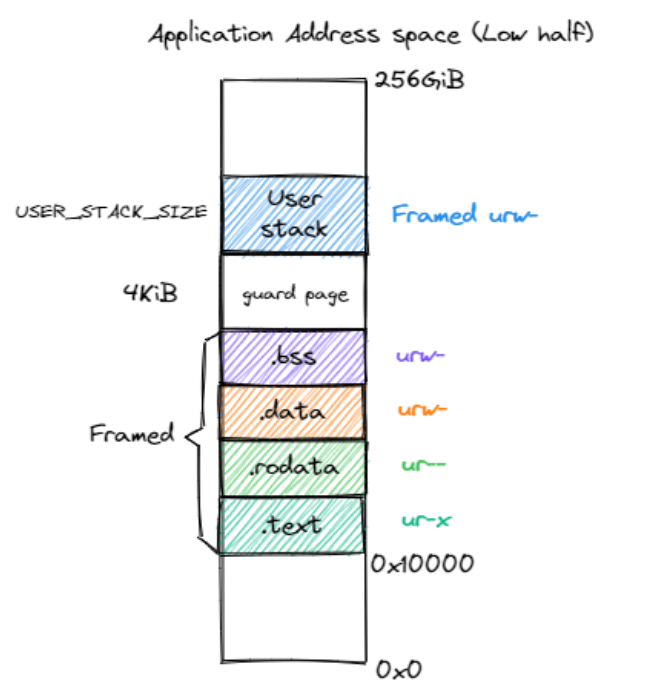 |
跳板机制
使能了分页机制之后,我们必须在trap过程中同时完成地址空间的切换。具体来说,当 __alltraps 保存 Trap 上下文的时候,我们必须通过修改 satp 从应用地址空间切换到内核地址空间,因为 trap handler 只有在内核地址空间中才能访问;同理,在 __restore 恢复 Trap 上下文的时候,我们也必须从内核地址空间切换回应用地址空间,因为应用的代码和数据只能在它自己的地址空间中才能访问,应用是看不到内核地址空间的。这样就要求地址空间的切换不能影响指令的连续执行,即要求应用和内核地址空间在切换地址空间指令附近是平滑的。
我们为何将应用的 Trap 上下文放到应用地址空间的次高页面而不是内核地址空间中的内核栈中呢?原因在于,在保存 Trap 上下文到内核栈中之前,我们必须完成两项工作:1)必须先切换到内核地址空间,这就需要将内核地址空间的 页表地址写入 satp 寄存器;2)之后还需要保存应用的内核栈栈顶的位置,这样才能以它为基址保存 Trap 上下文。这两步需要用寄存器作为临时周转,然而我们无法在不破坏任何一个通用寄存器的情况下做到这一点。因为事实上我们需要用到内核的两条信息:内核地址空间的 页表地址,以及应用的内核栈栈顶的位置,RISC-V却只提供一个 sscratch 寄存器可用来进行周转。所以,我们不得不将 Trap 上下文保存在应用地址空间的一个虚拟页面中,而不是切换到内核地址空间去保存。
Page fault
当CPU无法将虚拟地址转换为物理地址时,CPU会生成页面错误异常。RISC-V有三种不同类型的页面错误:加载页面错误(当加载指令无法转换其虚拟地址时)、存储页面错误(当存储指令无法转换其虚拟地址时)和指令页面错误(当指令的地址不转换时)。scause寄存器中的值指示页面错误的类型,而stval寄存器中包含无法转换的地址。
Cow(copy on write) Fork中的基本方案是让父子进程在最开始时共享所有物理页面,但将它们映射为只读。因此,当子进程或父进程执行存储指令时,RISC-V CPU会引发页面错误异常。作为对此异常的响应,内核会复制包含错误地址的页面。它将一个副本映射到子进程的地址空间中,并将另一个副本映射到父进程的地址空间中。在更新页表之后,内核在导致错误的指令处恢复出错进程。因为内核已经更新了相关的PTE以允许写入,所以出错指令现在将正常执行。
xv6中是如何设置stvec的
我们已经知道stvec寄存器保存的是中断服务程序的首地址,另外在U模式下,stvec必须指向的是uservec,在S模式下,stvec必须指向的是kernelvec,这样做的原因是需要在uservec切换页表。
那么xv6是如何设置stvec的呢?首先在uservec例程中除了执行保存上下文、切换页表等操作之外,还会在usertrap中将stvec指向kernelvec,这里的切换的目的是当前已经执行到了S模式,所有的中断、陷阱等都必须由kernelvec负责处理。
当需要返回usertrap时,usertrap会调用usertrapret,usertrapret会重新设置stvec的值使其指向uservec,之后跳转到userret,恢复上下文和切换页表。
第一次的stvec是如何设置的
在main中,cpu0调用了userinit()创建了第一个用户进程,并在scheduler中会切换到该进程。该进程的上下文中的ra(返回地址)被设置成了forkret(),当scheduler执行swtch函数时,会将进程上下文中的ra写入到ra寄存器中,这样当要从swtch()中返回时,就会返回到了forkret(),在forkret()中会直接调用usertrapret以实现stvec的设置和页表的切换。
与中断有关的硬件单元
在RISC v中,与中断有关的硬件单元主要有ACLINT、CLINT、PLIC、CLIC。
CLINT的全称是Core Local Interrupt,ACLINT的全称是Advanced Core Local Interrupt, CLIC的全称是Core-Local Interrupt Controller。
PLIC的全称Platform-Level Interrupt Controller。
尽管CLIC与PLIC名称相似,但是CLIC其实是为取代CLINT而设计的。ACLINT是为了取代SiFive CLINT而设计的,本质上讲,ACLINT相比于CLINT的优势就在于进行了模块化设计,将定时器和IPI功能分开了,同时能够支持NUMA系统。但是ACLINT和CLINT都还是RISC-V basic local Interrupts的范畴。
PLIC和CLIC的区别在于,前者负责的是整个平台的外部中断,CLIC负责的是每个HART的本地中断。
PLIC
ACLINT
ACLINT的规范翻译参见 RISC-V ACLINT
根据Linux RISC-V ACLINT Support的说法,大多数现有的 RISC-V 平台使用 SiFive CLINT 来提供 M 级定时器和 IPI 支持,而 S 级使用 SBI 调用定时器和 IPI。此外,SiFive CLINT 设备是一个单一的设备,所以 RISC-V 平台不能部分实现提供定时器和 IPI 的替代机制。RISC-V 高级核心本地中断器(ACLINT)尝试通过以下方式解决 SiFive CLINT的限制:
- 采用模块化方法,分离定时器和 IPI 功能为不同的设备,以便 RISC-V 平台可以只包括所需的设备
- 为 S 级 IPI 提供专用的 MMIO 设备,以便 SBI 调用可以避免在 Linux RISC-V 中使用 IPI
- 允许定时器和 IPI 设备的多个实例多sockets NUMA 系统
RISC-V ACLINT 规范向后兼容 SiFive CLINT。
CLIC
spec参见 riscv-fast-interrupt/clic.adoc
RISC-V 特权架构规范定义了 CSR,例如
***x***``ip、***x***``ie和中断行为。为这种 RISC-V 中断方案提供处理器间中断和定时器功能的简单中断控制器被称为 CLINT。当***x***``tvec.mode 设置为00或01时,本规范将使用术语 CLINT 模式。
在前文介绍mtvec时提到了mode字段,在RISC-V目前的特权级规范中,mode字段只能取00或01,其它值是reserved。从spec的描述中我们可以看出,mode字段无论是00还是01,都是CLINT模式,因此我们在前文介绍的有关中断的介绍都是CLINT模式(包括ACLINT)。
我目前不太清除CLIC是否在
时钟中断
“定时器中断”是由一个独立的计时器电路发出的信号,表示预定的时间间隔已经结束。计时器子系统将中断当前正在执行的代码。定时器中断可以由操作系统处理,用于实现时间片多线程,但是对于MTIME和MTIMECMP的读写只能由M-mode的代码实现,因此内核需要调用SBI的服务。
我相信你已经在RISC-V ACLIT已经了解到了时钟中断的基本原理,现在我们看一下如何处理时钟中断。
时钟中断相关的寄存器
https://tinylab.org/riscv-timer/
mtime需要以固定的频率递增,并在发生溢出时回绕。当mtime大于或等于mtimecmp时,由核内中断控制器 (CLINT, Core-Local Interrupt Controller) 产生 timer 中断。中断的使能由mie寄存器中的MTIE和STIE位控制,mip中的MPIE和SPIE则指示了 timer 中断是否处于 pending。在 RV32 中读取mtimecmp结果为低 32 位,mtimecmp的高 32 位需要读取mtimecmph得到。
由于mtimecmp只能在 M 模式下访问,对于 S/HS 模式下的内核和 VU/VS 模式下的虚拟机需要通过 SBI 才能访问,会造成较大的中断延迟和性能开销。为了解决这一问题,RISC-V 新增了 Sstc 拓展支持(已批准但尚未最终集成到规范中)。
Sstc 扩展为 HS 模式和 VS 模式分别新增了stimecmp和vstimecmp寄存器,当或者 是会产生timer中断,不再需要通过SBI陷入到其它模式。
时钟中断的基本处理过程
如下图所示是时钟中断的基本过程(xv6的处理过程):
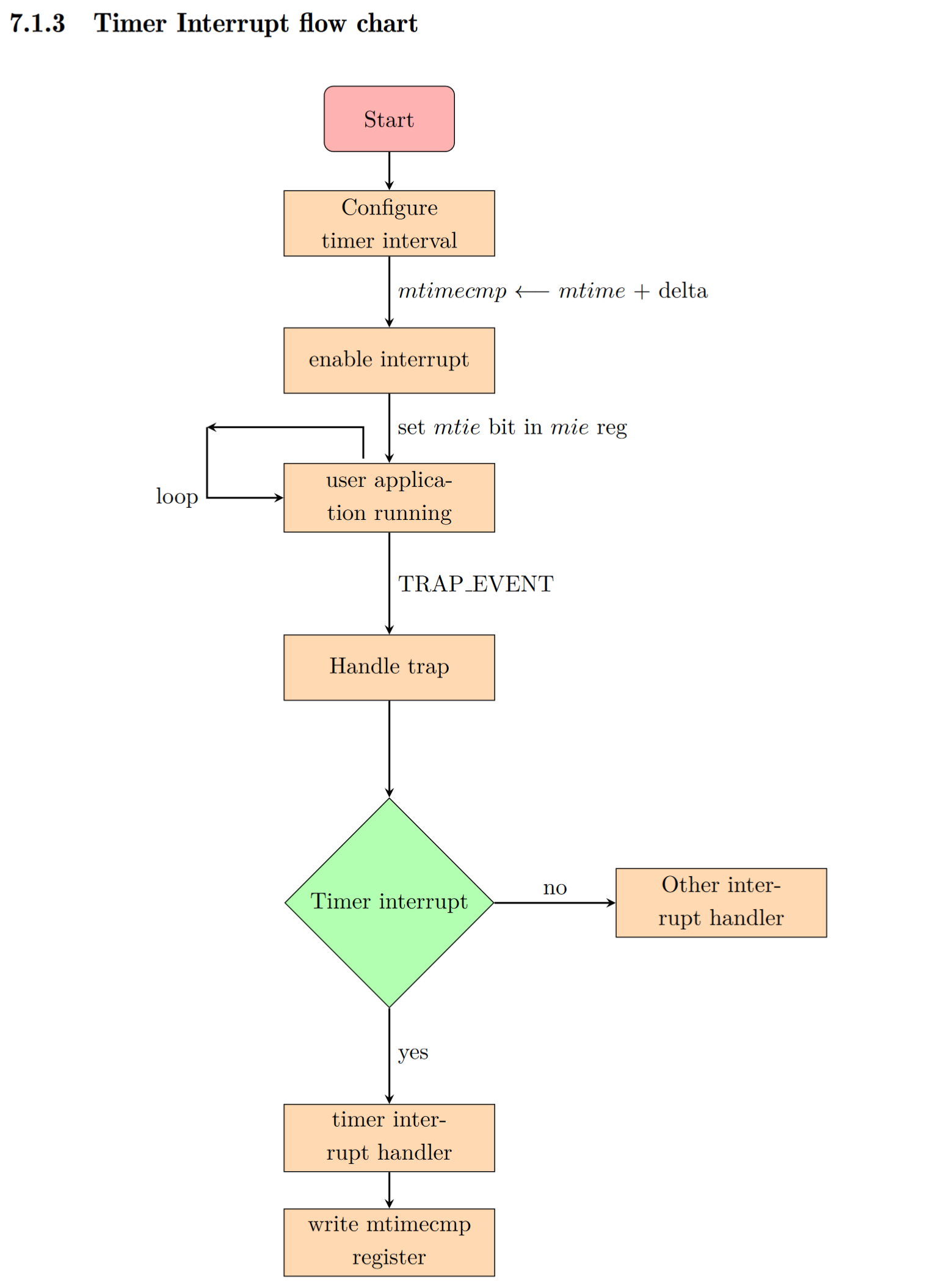
图源:https://shakti.org.in/docs/risc-v-asm-manual.pdf
让我们首先回顾一下有关timer的寄存器。首先要明确的是,timer的寄存器在timer设备里,不在CPU中,是通过MMIO的方式映射到内存中的。
mtime 寄存器是一个同步计数器。它从处理器上电开始运行,并以 tick 单位提供当前的实时时间。
mtimecmp 寄存器用于存储定时器中断应该发生的时间间隔。mtimecmp 的值与 mtime 寄存器进行比较。当 mtime 值变得大于 mtimecmp 时,就会产生一个定时器中断。mtime 和 mtimecmp 寄存器都是 64 位内存映射寄存器,因此可以直接按照内存读写的方式修改这两个寄存器的值。
xv6的实现
xv6对于时钟中断的处理方式是这样的:在M-mode设置好时钟中断的处理函数,当发生时钟中断时就由M-mode的代码读写mtime和mtimecmp,然后激活sip.SSIP以软件中断的形式通知内核。内核在收到软件中断之后会递增ticks变量,并调用wakeup函数唤醒沉睡的进程。 内核本身也会收到时钟中断,此时内核会判断当前运行的是不是进程号为0的进程,如果不是就会调用yield()函数使当前进程放弃CPU并调度下一个进程;如果使进程号为0的进程,那就不做处理。
timer_init
// core local interruptor (CLINT), which contains the timer.
#define CLINT 0x2000000L
#define CLINT_MTIMECMP(hartid) (CLINT + 0x4000 + 8*(hartid))
#define CLINT_MTIME (CLINT + 0xBFF8) // cycles since boot.
void
timerinit()
{
// each CPU has a separate source of timer interrupts.
int id = r_mhartid();
// ask the CLINT for a timer interrupt.
int interval = 1000000; // cycles; about 1/10th second in qemu.
// 我已经提过,mtimecmp 是映射到了物理地址中的,因此可以直接按照内存读写的方式
// 修改寄存器的值
// MTIME 寄存器映射到了 0x2000_BFF8
// 一块CPU有一个MTIME,所有的hart都共用这一个 MTIME
// MTIMECMP 的内存基地址是 0x2000000L
// 每个寄存器占 8个字节,每个hart都有一个MTIMECMP寄存器
// 因此呢,第id个(从0开始计数)的hart对应的 MTIMECMP 的寄存器的物理地址就是
// 0x2000000L + 8 * id
// 因此呢就容易理解下面的操作了,实际上就是根据 MTIME 初始化 MTIMECMP
*(uint64*)CLINT_MTIMECMP(id) = *(uint64*)CLINT_MTIME + interval;
// prepare information in scratch[] for timervec.
// scratch[0..2] : space for timervec to save registers.
// scratch[3] : address of CLINT MTIMECMP register.
// scratch[4] : desired interval (in cycles) between timer interrupts.
uint64 *scratch = &timer_scratch[id][0];
scratch[3] = CLINT_MTIMECMP(id);//记录当前hart对应的 MTIMECMP 寄存器映射到的物理地址
scratch[4] = interval;
w_mscratch((uint64)scratch);//将数组指针写入mscratch
// set the machine-mode trap handler.
w_mtvec((uint64)timervec);
// enable machine-mode interrupts.
w_mstatus(r_mstatus() | MSTATUS_MIE);
// enable machine-mode timer interrupts.
w_mie(r_mie() | MIE_MTIE);
}
时钟中断处理函数
在下面的代码中,首先是将mscratch与a0寄存器交换了值,此时a0保存的值就是个数组指针(这一点在前面的timer_init中已经分析了)。
timervec:
# start.c has set up the memory that mscratch points to:
# scratch[0,8,16] : register save area.
# scratch[24] : address of CLINT's MTIMECMP register.
# scratch[32] : desired interval between interrupts.
csrrw a0, mscratch, a0
# 保存寄存器的上下文
sd a1, 0(a0)
sd a2, 8(a0)
sd a3, 16(a0)
# schedule the next timer interrupt
# by adding interval to mtimecmp.
# 实际上执行的就是 MTIMECMP = MTIME + INTERVAL
ld a1, 24(a0) # CLINT_MTIMECMP(hart)
ld a2, 32(a0) # interval
ld a3, 0(a1)
add a3, a3, a2
sd a3, 0(a1)
# arrange for a supervisor software interrupt
# after this handler returns.
# 通过supervisor software 中断的方式通知 S-mode 的内核处理时钟中断
# 实际上呢,时钟中断已经在M-mode被处理掉了
# 之所以还要通知S-mode的内核是因为内核的进程调度器依赖于对时间的掌握
# S-mode只是根据时钟变化去做进程调度器相关的处理
li a1, 2
csrw sip, a1
# 恢复上下文
ld a3, 16(a0)
ld a2, 8(a0)
ld a1, 0(a0)
csrrw a0, mscratch, a0
mret
Linux的时钟中断的实现
参见 RISC-V timer 在 Linux 中的实现 - 泰晓科技
QEMU的时钟中断的逻辑
参见 https://wangzhou.github.io/riscv-timer的基本逻辑/
参考文献
- wangzhou.github.io
- RISC-V timer 在 Linux 中的实现 - 泰晓科技
- https://shakti.org.in/docs/risc-v-asm-manual.pdf
- RISC-V ACLINT Spec
- RISC-V Privileged Spec
软件中断
所谓软件中断就是软件触发的中断,也是所谓的核间中断(inter-process interrupt,IPI)。在RISC v中,核间中断是通过设置MIP的MSIP或者SSIP实现的。
下面以Linux和opensbi为例介绍S-MODE的软件中断的实现。
中断发送
Linux内核实现
在arch/riscv/kernel/smp.c中实现了ipi发送和处理的若干函数。
首先应当明确的是,IPI是核间中断,也就是一个核向另一个核发送的中断,那么就是软件运行时出于某种目的向另一个/些核发送了中断,那么就需要告知这个/些核,让这些核做某些事情,这就需要向其它核发送消息。
在smp.c中定义了枚举值:
enum ipi_message_type {
IPI_RESCHEDULE,
IPI_CALL_FUNC,
IPI_CPU_STOP,
IPI_IRQ_WORK,
IPI_TIMER,
IPI_MAX
};
从这些枚举值我们可以看出,一个软件中断可以传递5种不同的中断消息。
这些消息需要保存在变量里,因此在smp.c中也定义了静态变量ipi_data:
首先看静态变量ipi_data,该变量定义如下:
static struct {
unsigned long stats[IPI_MAX] ____cacheline_aligned;//记录对应类型的IPI收到了多少个
unsigned long bits ____cacheline_aligned;//记录对应的IPI是否被激活
} ipi_data[NR_CPUS] __cacheline_aligned;
从定义中我们可以看出,每个HART都有一个独立的ipi_data且是缓存行对齐的。其中stats记录了发送的软件中断的所传递的消息。在发送IPI之前,当前核心需要将信息写入到ipi_data变量中,这样当其它核心收到IPI并处理时,就可以根据ipi_data中记录的值进行相关操作。
这里我以向单个核发送IPI为例进行介绍:
static void send_ipi_single(int cpu, enum ipi_message_type op)
{
smp_mb__before_atomic();
set_bit(op, &ipi_data[cpu].bits);
smp_mb__after_atomic();
if (ipi_ops && ipi_ops->ipi_inject)
ipi_ops->ipi_inject(cpumask_of(cpu));
else
pr_warn("SMP: IPI inject method not available\n");
}
我们可以看到两个参数,第一个参数cpu是要发送到哪个核心的编号,op则是要传递的IPI类型。
set_bit就是激活对应的IPI类型。
这里比较关键的是调用了ipi_inject,这是个函数指针,该函数指针指向了sbi_send_cpumask_ipi函数。
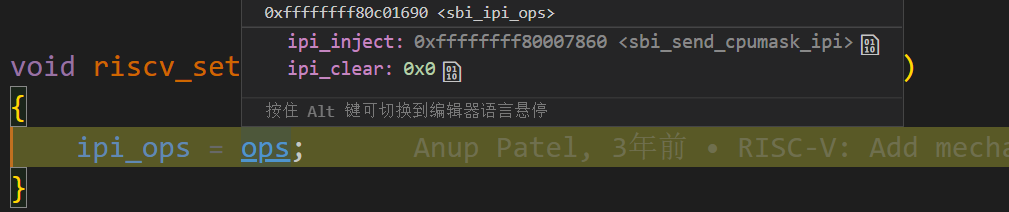
在arch/riscv/kernel/sbi.c中,我们看到sbi_send_cpumask_ipi也是一个函数指针,它的实现实际上与sbi的标准有关,比如有__sbi_send_ipi_v01,__sbi_send_ipi_v02等函数。
无论是哪种规范吧,反正最终是调用到了sbi,下面我们以opensbi为例继续介绍软件中断的过程。
Opensbi
在opensbi/lib/sbi/sbi_ipi.c中实现了ipi send的相关函数。
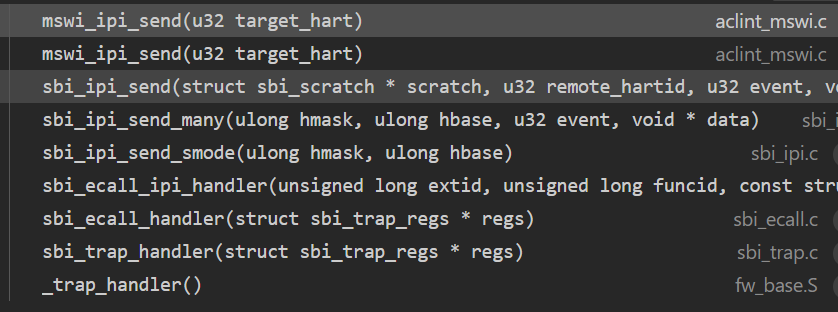
从调用函数栈中,可以看出,最终调用到了mswi_ipi_send函数:
static void mswi_ipi_send(u32 target_hart)
{
u32 *msip;
struct aclint_mswi_data *mswi;
if (SBI_HARTMASK_MAX_BITS <= target_hart)
return;
mswi = mswi_hartid2data[target_hart];
if (!mswi)
return;
/* Set ACLINT IPI */
msip = (void *)mswi->addr;
writel(1, &msip[target_hart - mswi->first_hartid]);
}
通过将CSR_MIP.SSIP置为就实现了S-MODE软件中断,因为根据RISC v的中断委托机制,中断会最终拉高CSR_SIP.SSIP,并在S-MODE对软件中断进行处理。下面我们来看Linux是如何对软件中断进行处理的。
中断处理
S-MODE的软件中断处理自然在Linux内核中。在arch/riscv/kernel/smp.c的handle_IPI函数就是软件中断处理函数。
void handle_IPI(struct pt_regs *regs)
{
unsigned long *pending_ipis = &ipi_data[smp_processor_id()].bits;
unsigned long *stats = ipi_data[smp_processor_id()].stats;
riscv_clear_ipi();//这里并不会丢失IPI,因为IPI发送的数量和激活状态已经记录在了ipi_data里面
// 下面就是对ipi的具体处理喽,读者有兴趣可自行查看
while (true) {
unsigned long ops;
/* Order bit clearing and data access. */
mb();
ops = xchg(pending_ipis, 0);
if (ops == 0)
return;
if (ops & (1 << IPI_RESCHEDULE)) {
stats[IPI_RESCHEDULE]++;
scheduler_ipi();
}
if (ops & (1 << IPI_CALL_FUNC)) {
stats[IPI_CALL_FUNC]++;[[osbidian 设置]]
generic_smp_call_function_interrupt();
}
if (ops & (1 << IPI_CPU_STOP)) {
stats[IPI_CPU_STOP]++;
ipi_stop();
}
if (ops & (1 << IPI_IRQ_WORK)) {
stats[IPI_IRQ_WORK]++;
irq_work_run();
}
#ifdef CONFIG_GENERIC_CLOCKEVENTS_BROADCAST
if (ops & (1 << IPI_TIMER)) {
stats[IPI_TIMER]++;
tick_receive_broadcast();
}
#endif
BUG_ON((ops >> IPI_MAX) != 0);
/* Order data access and bit testing. */
mb();
}
}
中断与异常的退出


SEE
SEE 是一种处理系统级别异常和中断的机制,例如处理器间中断(IPI)和虚拟内存异常。SEE 提供了一个专用的执行环境来处理这些异常和中断,该环境与正常的用户或内核执行环境分开。
在 RISC-V 系统中,异常和中断通常由内核或用户级别的异常处理程序处理。然而,某些异常和中断可能需要系统级别的干预或协调,例如需要将 IPI 传递到多个处理器线程(harts)的系统。
SEE 为处理这些类型的异常和中断提供了一个专用的执行环境。SEE 通常作为一个单独的硬件线程实现,运行在特权模式下,并具有访问系统级资源和数据结构的权限。当在系统级别发生异常或中断时,SEE 将被调用来处理异常或中断,并协调任何必要的系统级任务或操作。
SEE 的实现可能因使用的具体 RISC-V 系统和操作系统而异。但总的来说,SEE 提供了一个专用的环境来处理系统级别的异常和中断,并确保以安全和可控的方式处理这些事件。
By default, the xv6 operating system does not implement a System-Level Exception Environment (SEE). Instead, the xv6 kernel handles all exceptions and interrupts, including system-level exceptions and interrupts, directly. The kernel runs in privileged mode, which allows it to access and manage system-level resources and data structures.
However, the xv6 source code is open and modifiable, and it is possible to modify the kernel to implement a SEE if desired. Some researchers have developed modified versions of xv6 that include support for system-level exception handling or interprocessor interrupts (IPIs), such as MIT's "xv6-mp" implementation.
In general, adding SEE support to an operating system requires significant modifications to the kernel and low-level components of the system. This can be a complex and challenging task, and may require a deep understanding of the system architecture and hardware. Therefore, implementing a SEE in xv6, or any other operating system, should only be attempted by experienced developers with a strong understanding of operating system design and implementation.
Linux implements a System-Level Exception Environment (SEE), which is known as the kernel's interrupt handler. The interrupt handler is responsible for handling interrupts and exceptions that occur at the system level, such as inter-processor interrupts (IPIs) and virtual memory exceptions.
The Linux interrupt handler runs in privileged mode and has access to system-level resources and data structures. When an exception or interrupt occurs at the system level, the interrupt handler is invoked to handle the exception or interrupt and coordinate any necessary system-level tasks or actions.
The Linux interrupt handler is a complex and critical component of the kernel, and it has been designed to handle a wide variety of exceptions and interrupts in a safe and efficient manner. The interrupt handler is responsible for managing interrupt priorities, scheduling and dispatching interrupt handlers, and maintaining interrupt state and context.
The Linux interrupt handler is highly configurable and can be customized to support a wide range of system architectures and configurations. Interrupt handlers can be added or removed dynamically at runtime, and the kernel provides a number of APIs and interfaces for managing interrupts and exceptions.
In general, the Linux interrupt handler provides a robust and reliable mechanism for handling system-level exceptions and interrupts, and ensures that these events are handled in a safe and controlled manner.
IPI
In Linux, Inter-Processor Interrupts (IPIs) are implemented using a combination of hardware and software mechanisms.
At the hardware level, modern CPUs typically provide support for IPIs through dedicated interrupt lines or message-signaled interrupts (MSIs). These mechanisms allow one CPU to send an interrupt signal to another CPU, which can then handle the interrupt in a dedicated interrupt handler.
In Linux, IPIs are managed by the kernel's interrupt handler, which is responsible for handling interrupts and exceptions that occur at the system level, including IPIs. When an IPI is received, the interrupt handler is invoked to handle the interrupt and coordinate any necessary system-level tasks or actions.
To send an IPI in Linux, the kernel provides a number of interfaces and APIs that can be used by user-level or kernel-level programs. For example, the send_IPI_*() functions can be used to send IPIs to specific CPUs or groups of CPUs, while the smp_call_function_*() functions can be used to execute a function on a specific CPU or group of CPUs using IPIs.
When an IPI is received, the Linux interrupt handler checks the interrupt type and dispatches the appropriate interrupt handler. For example, IPIs may be used to signal a memory barrier or cache flush operation, to synchronize system clocks, or to perform other system-level tasks.
In general, the Linux IPI mechanism provides a reliable and efficient way to coordinate inter-processor communication and synchronization, and allows multi-CPU systems to perform complex tasks in a coordinated and efficient manner.
在田宇所著的《一个64位操作系统的设计与实现》第12章系统介绍了多核处理器以及IPI。
Software interrupt
Yes, you are correct. Software interrupts, also known as traps or system calls, are events that are generated by the CPU when it executes specific instructions, such as the ecall and break instructions in RISC-V. Unlike exceptions, which are generated by the CPU in response to exceptional conditions such as division by zero or invalid memory access, software interrupts are generated intentionally by the running program or operating system.
When a software interrupt is generated, the CPU sets a flag or raises an interrupt signal to indicate the interrupt to the operating system. The operating system then typically saves the current context of the program, such as the program counter and register values, and switches to a higher privilege level to execute the interrupt service routine. The interrupt service routine is a piece of code that is designed to handle the specific interrupt and perform any necessary actions, such as servicing a system call or responding to a user input event.
The mechanism for handling interrupts, exceptions, and software interrupts is typically similar across different ISAs and operating systems. When an interrupt occurs, the current context is saved and the execution flow is redirected to the interrupt service routine. After the interrupt is handled, the context is restored and execution resumes from where it left off.
In summary, software interrupts are intentional events generated by executing specific instructions, and are used to trigger a mechanism that changes the privilege level and redirects the execution flow to a routine designed to handle the interrupt.
User-Level interrupt
上一节叙述的是在M-S-U的CPU中的标准中断,这一节描述用户态中断。
用户态中断是N Standard Extension,相关实现可以参考https://github.com/TRCYX/riscv-user-level-interrupt 和 https://gallium70.github.io/rv-n-ext-impl/ch1_1_priv_and_trap.html
事实上用户态中断比较罕见,但是x86已经完全支持用户态中断了。
与用户态中断有关的寄存器有:ustatus, uip, uie, sedeleg, sideleg, uscratch, uepc, utevc, utval。其中sedeleg和sideleg就是为实现用户态中断而添加的,如果S-mode不委托异常、中断到U-mode,那么用户态中断是无法实现的。sedeleg/sideleg与medeleg/mideleg是完全一致的,不赘述。
uscratch/uepc/utevc/utval与相应的M-mode的寄存器也是一致的,不再赘述。这里仅重点介绍ustatus, uip, uie。
ustatus

ustatus是很简单的,就两个值得注意的字段UPIE和UIE。如果UIE为0就禁用用户态中断,否则启用用户态中断。在处理用户态中断时,使用UPIE记录UIE,之后会将UIE置零。值得注意的是,ustatus里面没有UPP,因为没有比U-mode更低的特权级了,陷入到U-mode的一定是U-mode的特权级,因此也就没有必要记录发生中断前的特权级了。
uip与uie
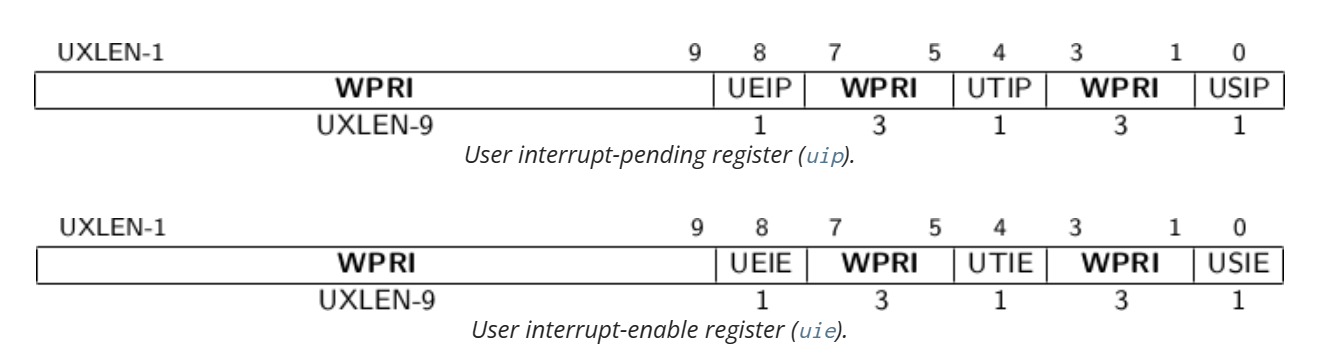
本规范定义了三种中断类型:软件中断、定时器中断和外部中断。可以通过向 uip 寄存器的用户软件中断挂起(USIP)位写入 1,来触发当前处理器上的用户级软件中断。可以通过向 uip 寄存器的 USIP 位写入 0,来清除挂起的用户级软件中断。当 uie 寄存器中的 USIE 位清零时,用户级软件中断将被禁用。
ABI 应该提供一种机制,以发送处理器间中断到其他处理器,从而最终导致接收处理器的 uip 寄存器中的 USIP 位被设置。
除了 uip 寄存器中的 USIP 位之外,其余所有位都是只读的。
如果 uip 寄存器中的 UTIP 位被设置,则表示用户级定时器中断挂起。当 uie 寄存器中的 UTIE 位清零时,将禁用用户级定时器中断。ABI 应该提供一种机制来清除挂起的定时器中断。
如果 uip 寄存器中的 UEIP 位被设置,则表示用户级外部中断挂起。当 uie 寄存器中的 UEIE 位清零时,将禁用用户级外部中断。ABI 应该提供一些方法来屏蔽、解除屏蔽和查询外部中断的原因。
uip 和 uie 寄存器是 mip 和 mie 寄存器的子集。读取 uip/uie 的任何字段或写入其任何可写字段,都会导致 mip/mie 中同名字段的读写。如果实现了 S 模式,则 uip 和 uie 寄存器也是 sip 和 sie 寄存器的子集。