MapReduce
论文基本信息
| 类别 | 描述 |
|---|---|
| 名称 | MapReduce: Simplified Data Processing on Large Clusters |
| 期刊 | USNIX OSDI ’04: 6th Symposium on Operating Systems Design and Implementation |
| 期刊级别 | CCFA |
| 发表时间 | 2008 |
| 第一作者 | Jeffrey Dean and Sanjay Ghemawat |
| 第一作者单位 |
声明
本文为本人原创,未经授权严禁转载。如需转载需要在文章最前面注明本文原始链接。
摘要
MapReduce 是一种用于处理和生成大型数据集的编程模型及相关实现。用户指定一个映射函数(map function)来处理键值对以生成一组中间键值对,并指定一个规约函数(reduce function)来合并所有与相同中间键关联的中间值。
用这种函数式风格编写的程序会自动并行化并在大量商用机器集群上执行。运行时系统负责处理划分输入数据、在机器集合中调度程序执行、处理机器故障和管理所需的机器间通信等细节。这能让没有并行和分布式系统经验的程序员轻松利用大型分布式系统的资源。
我们实现的 MapReduce 运行在一个大型的商用机器集群上,具有极高的可扩展性:一个典型的 MapReduce 计算可在数千台机器上处理很多 TB 的数据。程序员发现这个系统很容易使用:数百个 MapReduce 程序已经实现,每天有超过一千个 MapReduce 作业在谷歌集群上执行。
研究目标
问题
贡献
这项工作的主要贡献是一个简单而强大的接口,可以实现大规模计算的自动并行化和分布式化,并结合了在这个接口上实现的高性能,可在大量商用 PC 集群上实现。
方法
编程模型
计算任务是:输入一组键值对,输出一组键值对。
Map函数由用户编写,用于生成中间键值对,MapReduce库将中间键值对中具有相同key的values进行聚合(group),并将他们传递给Reduce函数。
Reduce函数由用户编写,接受中间键值对,将相同key的values形成更小的一组values.
上述过程可形式化描述为:
例如:

实现
执行流程
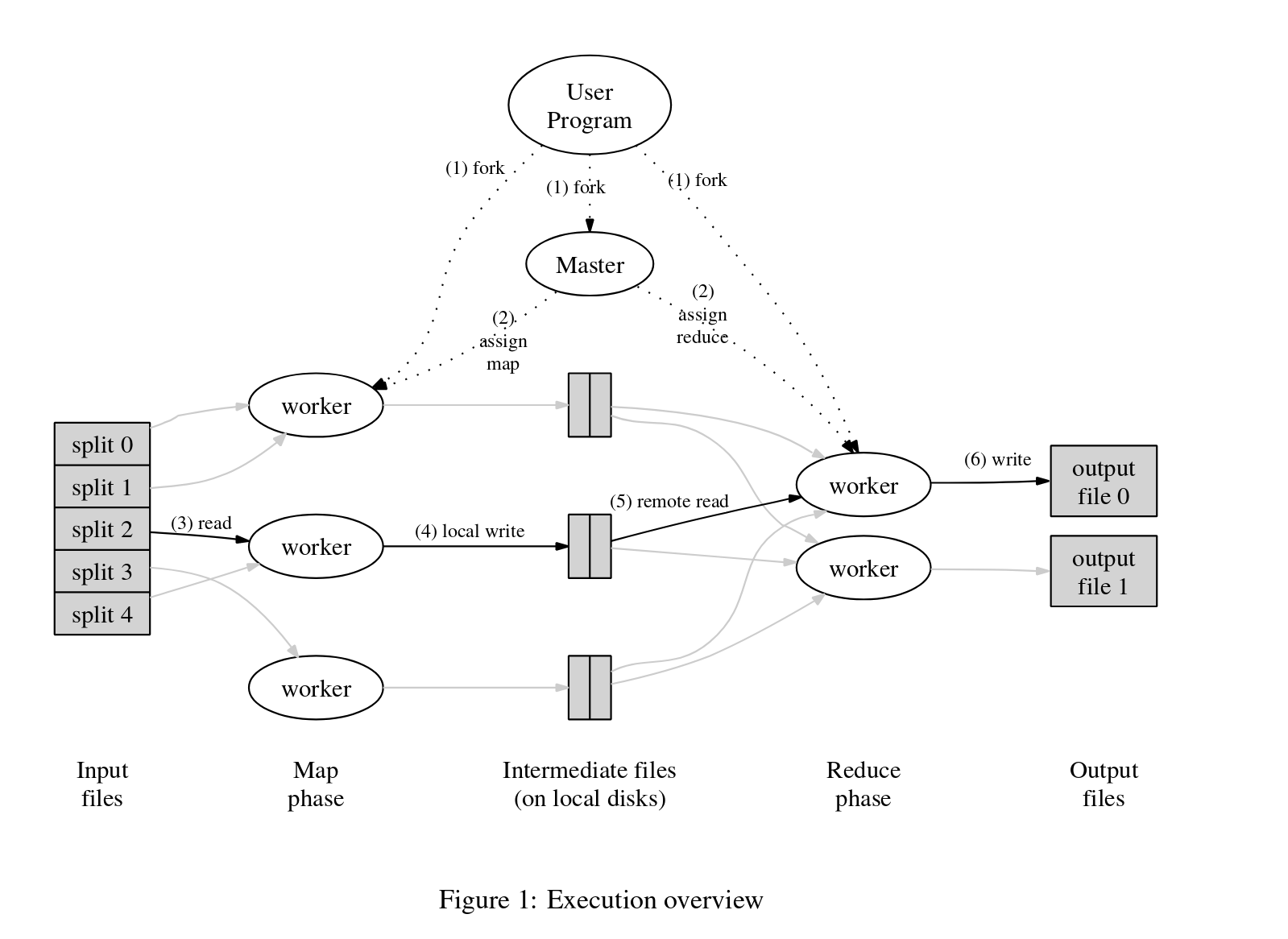
当用户程序调用 MapReduce 函数时,会发生以下一系列动作(图 1 中的编号标签对应于以下列表中的编号):
- 用户程序中的 MapReduce 库将输入文件拆分为 M 份,每份通常为 16 兆字节到 64 兆字节(MB);然后在计算机集群上启动这个程序的多个副本。
- 程序的一个副本是 master,其余的由 master 分配工作的 workers。有 M 个 map 任务和 R 个 reduce 任务要分配。master 选择空闲的 workers,并为每一个分配一个 map 任务或 reduce 任务。
- 被分配了 map 任务的 worker 读取相应输入。它从输入数据中解析出键/值对,并将每对传递给用户定义的 Map 函数。Map 函数产生的中间键/值对缓存在内存中。
- 缓冲的键/值对被周期性地写入本地磁盘,并由分区函数分区成 R 个区域。这些缓冲的键/值对在本地磁盘上的位置被传回给 master,master 负责将这些位置转发给 reduce workers。
- 当 reduce worker 从 master 那里收到这些位置的通知时,它使用远程过程调用从 map worker 的本地磁盘中读取缓冲的数据。当一个 reduce worker 读取了所有中间数据后,它按中间键对数据进行排序,以便所有具有相同键的数据都被分组在一起。排序是必要的,因为通常许多不同的键都映射到同一个 reduce 任务。如果中间数据量太大而无法放入内存,则使用外部排序。
- reduce worker 迭代排序后的中间数据,并为遇到的每个唯一的中间键,将该键和相应的一组中间值传递给用户的 Reduce 函数。Reduce 函数的输出被附加到此 reduce 分区的一个最终输出文件中。
- 当所有 map 任务和 reduce 任务都已完成时,master 唤醒用户程序。此时,用户程序中的 MapReduce 调用返回给用户代码。
master数据结构
master 维护着几个数据结构。对于每个 map 任务和 reduce 任务,它存储状态(空闲、进行中或已完成)和 worker 机器(对于非空闲任务)的身份。master 是一个管道,通过它将中间文件区域的位置从 map 任务传播到 reduce 任务。因此,对于每个已完成的 map 任务,master 会存储该 map 任务产生的 R 个中间文件区域的位置和大小。随着 map 任务的完成,会收到对此位置和大小信息的更新。这些信息会增量地推送到具有正在进行的 reduce 任务的 worker。
fault tolerance
master 定期 ping 每个 worker。如果在一定时间内没有从 worker 收到响应,master 会将该 worker 标记为已失败。worker 完成的任何 map 任务都会重置回其初始的空闲状态,因此可以调度到其他 worker 上。同样,在失败的 worker 上正在进行的任何 map 任务或 reduce 任务也会重置为空闲并可以重新调度。已完成的 map 任务在发生故障时会重新执行,因为它们的输出存储在故障机器的本地磁盘上,因此无法访问。已完成的 reduce 任务无需重新执行,因为它们的输出存储在全局文件系统中。假如正在执行map人物的worker A失败了,然后被B重新执行了,那么所有的正在执行reduce人物的worker都会收到重新调度的通知。
每个正在进行的任务将其输出写入私有临时文件。reduce 任务生成一个这样的文件,而 map 任务生成 R 个这样的文件(每个 reduce 任务一个)。map 任务完成后,worker 将向 master 发送一条消息,并在消息中包含 R 个临时文件的名字。如果 master 收到一条已经完成的 map 任务的完成消息,它将忽略该消息。否则,它会将 R 个文件的名字记录在 master 数据结构中。reduce 任务完成后,reduce worker 会原子地将其临时输出文件重命名为最终输出文件。如果在多台机器上执行同一个 reduce 任务,那么会针对同一个最终输出文件执行多个重命名调用。我们依靠底层文件系统提供的原子重命名操作来保证最终文件系统状态仅包含一次 reduce 任务执行所生成的数据。
我们绝大多数的 map 和 reduce 运算符都是确定性的,并且在这种情况下,我们的语义等价于顺序执行,这使得程序员很容易推理出程序的行为。当 map 和/或 reduce 运算符是非确定性时,我们提供了更弱但仍然合理的语义。在存在非确定性运算符的情况下,特定 reduce 任务 R1 的输出等价于由非确定性程序的顺序执行所产生的 R1 的输出。但是,不同 reduce 任务 R2 的输出可能对应于由非确定性程序的不同顺序执行所产生的 R2 的输出。
其他要考虑的点
在论文中考虑了在带宽限制、任务划分粒度、部分机器执行速度过慢导致掉队等问题,这里不再一一阐述。
此外还有:分区函数(如何对数据进行划分)、键值对排序函数、combiner函数(聚合函数,在将数据发送给reduce之前进行聚合,一般情况下聚合函数与reduce函数相同,不同的是聚合函数是在map函数执行的worker上执行的)、输入输出格式等问题。
详细的内容请参见论文,这些考虑太过琐碎了。
实验
结论
未来与展望
强相关文献
| 名称 | 链接 | 说明 |
|---|---|---|
| MIT分布式系统课程 | https://pdos.csail.mit.edu/6.824/labs/lab-mr.html | 要求实现一个MapReduce |
| MIT课程的源码实现 | https://github.com/wangzhankun/mit-6.824-distributed-system/releases/tag/mapreduce-complete |